









विषय-सूची
पायथन में, एक पंक्ति के अंत को चिह्नित करने और एक नई शुरुआत करने के लिए, आपको एक विशेष वर्ण का उपयोग करने की आवश्यकता है। साथ ही, यह जानना महत्वपूर्ण है कि विभिन्न पायथन फाइलों के साथ काम करते समय इसका सही तरीके से उपयोग कैसे करें, और इसे आवश्यक क्षणों में कंसोल में प्रदर्शित करें। प्रोग्राम कोड के साथ काम करते समय नई लाइनों के लिए सीमांकक का उपयोग कैसे करें, इसके बारे में विस्तार से समझना आवश्यक है, क्या इसका उपयोग किए बिना पाठ जोड़ना संभव है।
न्यूलाइन कैरेक्टर के बारे में सामान्य जानकारी
n एक नई लाइन पर जानकारी लपेटने और पायथन में पुरानी लाइन को बंद करने का प्रतीक है। इस प्रतीक में दो तत्व होते हैं:
- उल्टा तिरछा;
- n एक लोअरकेस वर्ण है।
इस वर्ण का उपयोग करने के लिए, आप "प्रिंट (एफ" हेलोनवर्ल्ड!") अभिव्यक्ति का उपयोग कर सकते हैं, जिसके कारण आप एफ-लाइनों में जानकारी स्थानांतरित कर सकते हैं।
प्रिंट फ़ंक्शन क्या है
अतिरिक्त सेटिंग्स के बिना, डेटा ट्रांसफर कैरेक्टर को अगली पंक्ति में हिडन मोड में जोड़ा जाता है। इसके कारण, इसे एक निश्चित फ़ंक्शन को सक्रिय किए बिना लाइनों के बीच नहीं देखा जा सकता है। प्रोग्राम कोड में विभाजक चिह्न प्रदर्शित करने का एक उदाहरण:
प्रिंट ("हैलो, वर्ल्ड"!") - "हैलो, वर्ल्ड!" एनवहीं, इस चरित्र की ऐसी खोज पायथन की बुनियादी विशेषताओं में लिखी गई है। "प्रिंट" फ़ंक्शन का "अंत" पैरामीटर के लिए एक डिफ़ॉल्ट मान है - n। यह इस फ़ंक्शन के लिए धन्यवाद है कि यह वर्ण डेटा को अगली पंक्तियों में स्थानांतरित करने के लिए पंक्तियों के अंत में सेट किया गया है। "प्रिंट" फ़ंक्शन की व्याख्या:
प्रिंट (* ऑब्जेक्ट्स, सितंबर = '' ', एंड = 'एन', फाइल = sys.stdout, फ्लश = गलत)
"प्रिंट" फ़ंक्शन से "अंत" पैरामीटर का मान वर्ण "एन" के बराबर है। प्रोग्राम कोड के स्वचालित एल्गोरिदम के अनुसार, यह अंत में पंक्तियों को पूरा करता है, जिसके पहले "प्रिंट" फ़ंक्शन लिखा जाता है। एकल "प्रिंट" फ़ंक्शन का उपयोग करते समय, आप इसके कार्य के सार को नोटिस नहीं कर सकते हैं, क्योंकि स्क्रीन पर केवल एक पंक्ति प्रदर्शित की जाएगी। हालाँकि, यदि आप इस तरह के कुछ कथन जोड़ते हैं, तो फ़ंक्शन का परिणाम अधिक स्पष्ट हो जाता है:
प्रिंट ("हैलो, वर्ल्ड 1!") प्रिंट ("हैलो, वर्ल्ड 2!") प्रिंट ("हैलो, वर्ल्ड 3!") प्रिंट ("हैलो, वर्ल्ड 4!")उपरोक्त कोड के परिणाम का एक उदाहरण:
हैलो, विश्व 1! हैलो, वर्ल्ड 2! हैलो, वर्ल्ड 3! हैलो, विश्व 4!
प्रिंट के साथ एक न्यूलाइन कैरेक्टर को बदलना
"प्रिंट" फ़ंक्शन का उपयोग करके, लाइनों के बीच विभाजक वर्ण का उपयोग नहीं करना संभव है। ऐसा करने के लिए, आपको फ़ंक्शन में ही "अंत" पैरामीटर को बदलना होगा। इस मामले में, "अंत" मान के बजाय, आपको एक स्थान जोड़ने की आवश्यकता है। इसके कारण, यह वह स्थान है जो "अंत" वर्ण को प्रतिस्थापित करेगा। डिफ़ॉल्ट सेटिंग सेट के साथ परिणाम:
>>> प्रिंट ("हैलो") >>> प्रिंट ("वर्ल्ड") हैलो वर्ल्डएक स्थान के साथ "n" वर्ण को बदलने के बाद परिणाम प्रदर्शित करना:
>>> प्रिंट ("हैलो", अंत = "") >>> प्रिंट ("वर्ल्ड") हैलो वर्ल्डएक पंक्ति में मानों के अनुक्रम को प्रदर्शित करने के लिए वर्णों को बदलने की इस पद्धति का उपयोग करने का एक उदाहरण:
for i in range(15): if i <14: print(i, end=", ") else: Print(i)
फाइलों में विभाजक चरित्र का उपयोग करना
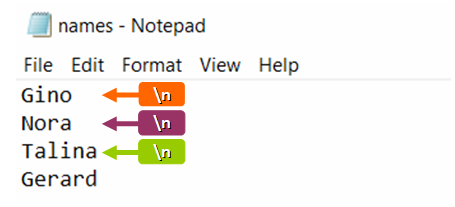
प्रतीक जिसके बाद प्रोग्राम कोड का पाठ अगली पंक्ति में स्थानांतरित किया जाता है, तैयार फाइलों में पाया जा सकता है। हालाँकि, प्रोग्राम कोड के माध्यम से दस्तावेज़ को देखे बिना, इसे देखना असंभव है, क्योंकि ऐसे वर्ण डिफ़ॉल्ट रूप से छिपे होते हैं। न्यूलाइन कैरेक्टर का उपयोग करने के लिए, आपको नामों से भरी एक फाइल बनानी होगी। इसे ओपन करने के बाद आप देख सकते हैं कि एक नई लाइन पर सभी नाम शुरू हो जाएंगे। उदाहरण:
नाम = ['पेट्र', 'दीमा', 'आर्टेम', 'इवान'] खुले ("names.txt", "w") के साथ f: नामों में नाम के लिए [: -1]: f.write (f) "{name}n") f.लिखें (नाम[-1])नाम इस तरह से तभी प्रदर्शित होंगे जब टेक्स्ट फ़ाइल को अलग-अलग पंक्तियों में जानकारी को अलग करने के लिए सेट किया गया हो। यह स्वचालित रूप से प्रत्येक पिछली पंक्ति के अंत में छिपे हुए वर्ण "n" को सेट कर देगा। छिपे हुए चिह्न को देखने के लिए, आपको फ़ंक्शन को सक्रिय करने की आवश्यकता है - ".readlines ()"। उसके बाद, प्रोग्राम कोड में सभी छिपे हुए वर्ण स्क्रीन पर प्रदर्शित होंगे। फ़ंक्शन सक्रियण उदाहरण:
f: प्रिंट (f.readlines ()) के रूप में खुले ("names.txt", "r") के साथ
सलाह! पायथन के साथ सक्रिय रूप से काम करते हुए, उपयोगकर्ता अक्सर ऐसी स्थितियों का सामना करते हैं जहां प्रोग्राम कोड को एक लंबी लाइन में लिखा जाना चाहिए, लेकिन इसकी समीक्षा करना और अलग किए बिना अशुद्धियों की पहचान करना बेहद मुश्किल है। ताकि एक लंबी लाइन को अलग-अलग टुकड़ों में विभाजित करने के बाद, कंप्यूटर इसे संपूर्ण मानता है, मूल्यों के बीच प्रत्येक मुक्त अंतर में, आपको "" - एक बैकस्लैश वर्ण सम्मिलित करना होगा। एक चरित्र जोड़ने के बाद, आप दूसरी पंक्ति में जा सकते हैं, कोड लिखना जारी रख सकते हैं। लॉन्च के दौरान, प्रोग्राम स्वयं अलग-अलग टुकड़ों को एक पंक्ति में इकट्ठा करेगा।
एक स्ट्रिंग को सबस्ट्रिंग में विभाजित करना
एक लंबी स्ट्रिंग को कई सबस्ट्रिंग में विभाजित करने के लिए, आप स्प्लिट विधि का उपयोग कर सकते हैं। यदि कोई और संपादन नहीं किया जाता है, तो डिफ़ॉल्ट सीमांकक एक स्थान है। इस विधि को क्रियान्वित करने के बाद, चयनित टेक्स्ट को सबस्ट्रिंग द्वारा अलग-अलग शब्दों में विभाजित किया जाता है, स्ट्रिंग्स की सूची में परिवर्तित किया जाता है। उदाहरण के तौर पे:
स्ट्रिंग = "कुछ नया टेक्स्ट" स्ट्रिंग्स = स्ट्रिंग। स्प्लिट () प्रिंट (स्ट्रिंग्स) ['कुछ', 'नया', 'टेक्स्ट']
रिवर्स ट्रांसफ़ॉर्मेशन करने के लिए, जिसकी मदद से सबस्ट्रिंग की सूची एक लंबी स्ट्रिंग में बदल जाएगी, आपको जॉइन विधि का उपयोग करना चाहिए। स्ट्रिंग्स के साथ काम करने का एक अन्य उपयोगी तरीका स्ट्रिप है। इसके साथ, आप लाइन के दोनों किनारों पर स्थित रिक्त स्थान को हटा सकते हैं।
निष्कर्ष
पायथन में काम करते समय एक नई लाइन से कुछ डेटा आउटपुट करने के लिए, पुरानी लाइन को "एन" अक्षर के साथ समाप्त करना आवश्यक है। इसकी मदद से, संकेत के बाद की जानकारी अगली पंक्ति में स्थानांतरित हो जाती है, और पुरानी बंद हो जाती है। हालाँकि, डेटा स्थानांतरित करने के लिए इस प्रतीक का उपयोग करना आवश्यक नहीं है। ऐसा करने के लिए, आप पैरामीटर का उपयोग कर सकते हैं end = "